Posted on : March 3rd 2023
How Enterprises Leverage Web Scrapping to Their Benefit
In this data-driven digital age, extracting data from websites is indispensable for enterprises to gain an information advantage. The volume of this data is growing at warp speed and web scraping is the first step that helps enterprises make sense of this exponentially growing data.
Web scraping helps collect many types of data such as images, videos, specific numbers and tables, product information, customer sentiments and reviews, and pricing from comparison websites. More specifically, web scraping helps gather business cycle data, economic and financial data, oil and gas production, and more.
There are many applications for web scraping. For example, market research companies use this technique to gather data from social media or forums for customer sentiment analysis. Other companies scrape data from product sites for competitor analysis. Web scraping represents an excellent tool for scraping medicine details from pharmaceutical websites. In the real estate sector, the practice helps collect precise, credible, and accurate property and consumer data. There are more such applications across industries.
What Is Web Scraping?
Web scraping is a data extraction process for collecting raw data that is generated from various processes on websites. This raw data would be going through multiple stages of cleaning, and pre-processing to analyze and derive insights for a specific use case. Besides web scraping, this process is known as web crawling, web harvesting, screen or data scraping, and more.
Web scraping techniques enable data analysis and business process re-engineering downstream. Furthermore, these techniques allow enterprises to gather a large amount of user-generated data from social media platforms, enterprise business applications, mobile apps, websites, portals, sensors, and online forums.
A typical data-driven project follows the lifecycle given in Figure-1, with web scraping playing a major and first important role in the journey. To quote a cliché, ‘garbage in and garbage out’, what you feed in as knowledge to machines is what it learns. Therefore, it is important to remember, if we put bad information into our computer models, the outcome will be bad insights and poor insights.
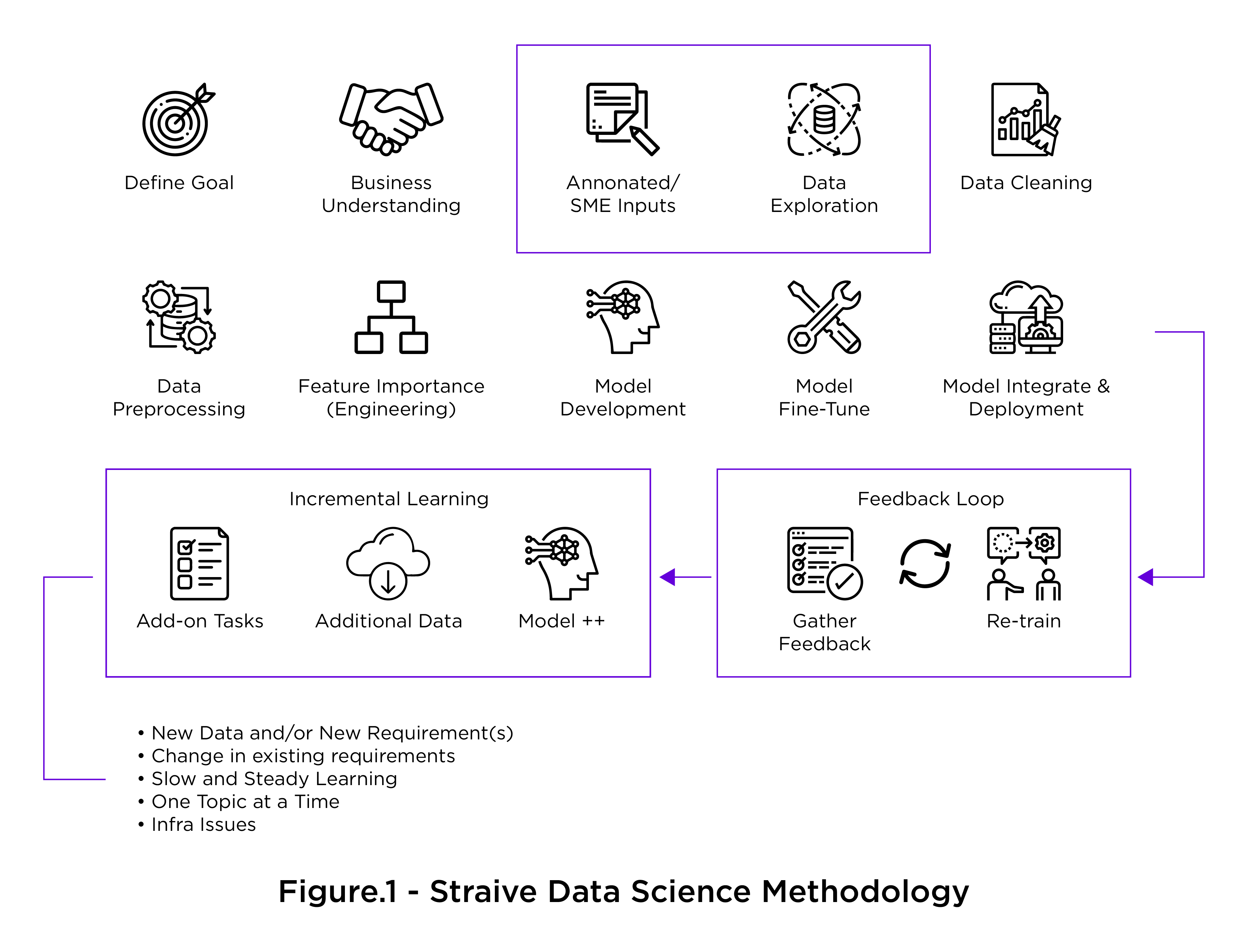
Why Is Web Scraping Essential?
For any important and valuable business decision-making, access to relevant quality data is of great importance. This data enables enterprises to make informed decisions, enrich customer relationships, enhance the usability of products and services, improve productivity, and enable operational excellence. Web scraping is a part of many data science projects as it is essential to data science and machine learning. Moreover, many data scientists rely on web scrapers as data science projects begin with collecting data. Let’s take it one step further, Whether you’re a developer, researcher, data analyst, or marketer, web scraping is an invaluable tool for getting the right data.
Where Does Straive Step In?
Straive has significant experience managing/maintaining large/complex directories and monitoring executive movement or tracking events. Our real-time monitoring solution supports critical data needs such as monitoring the price information of stocks and commodities, corporate actions, and time-sensitive schedules.
Key Differentiators of Straive Web Scraping Service:
- Provides automated website monitoring feature to track and trigger alerts on changes to websites
- Integrates with downstream platforms for cleansing, standardization, and disambiguation
- Needs no customization for scraping content in English, German, Spanish, Italian, Russian, Chinese, Japanese, Korean & Portuguese
- Scrapes paginated sources intuitively
- Extracts content via RPA scripts where repetitive actions are involved
- Provides generic scripts-single scripts for extracting information from multiple sites where the same entities are involved

Introducing the Straive Data Platform (SDP)
The Straive Data Platform (SDP) is integral to Straive’s data extraction service. Data from various sources – unstructured data such as documents, emails, news articles, or feeds and structured enterprise data like client APIs or news feeds – are ingested into the platform using data connectors.
Considering that the internet is rich in data published directly by governments, businesses, re-publishers, and individuals, our SDP platform has built-in modules to scrape online public sources such as regulatory portals, company pages, and news sites.
SDP uses a proprietary-built crawler engine to crawl data across various processes for public information such as:
- Metadata
- Contact profiles
- Documents
- Subsidiaries
- Class action lawsuits
- Management changes
- Journal/book articles from digital repositories
Multiple blue-chip clients have deployed SDP scale for scraping data from over 12 million web pages. It has collected over 50 million data points on companies, people, products, and locations. Furthermore, SDP is used for monitoring around 610,000 web sources daily.
Some of the key web scraping technologies Straive explores are Scrapy, Selenium, Zyte, and Beautiful Soup from Python libraries in addition to inbuilt RPA solutions.
What Is the Scope of Straive’s Web-Scraping Services?
Straive’s web-scraping services are customizable for most business needs. For example:
- If you are an E-commerce business, we could track your competitor’s prices and help you analyze their pricing trends and help come up with competitive prices
- If you are a manufacturer looking to keep an eye on the retailers’ pricing strategy then we will help you monitor their MAP compliance
- If you are into creative graphic designing and require timely access to specific types of images then guess what, we are here to automate the entire process
- If you are a service provider and getting to know your customers’ sentiments is very vital, we will help you track and analyze customer sentiment by timely extracting consumer feedback and reviews
- If you are a data aggregator, SDP enables you to scrape data from various search portals (e.g. Google, Zomato, etc) in a more quality and quantitative manner ( Download Case Study and learn how Straive enabled a leading provider of firmographic data to deliver high-quality data to their customers.)
- If you are a market leader looking to assess a company’s ESG score, SDP helps to scrape reports like annual reports, 10K reports, CSR reports, meeting notices, AGM notices, and more from thousands of companies across the world. As a downstream text intelligent feature, SDP extracts and curates domain-driven information from these documents (E.g. ESG, Chemical, Books)
So What Are You Waiting For?
From aggregating news articles, market data aggregation, extracting financial statements, and insurance risk determination to real-time analytics, and much more we are your one-stop shop for web scraping needs. We specialize in saving enterprises invaluable time and money through our managed data extraction and ethical web scraping services.
Our team of web scraping professionals will gather valuable information from an extensive range of online platforms so that your team is up-to-date with the latest datasets that will give you a competitive edge. Our approach is geared toward handling the entire data scraping process so that you can focus on providing an excellent customer experience.
Our web scraping services can be summarized as – show us the website, tell us the data you want to collect, and leave the rest to Straive. We will deliver accurate, timely, high-quality, and ready-to-use data in the shortest possible time.
You can learn more about Straive’s web scraping capabilities at https://www.straive.com/technology/straive-data-platform/data-extraction-services or contact us at straiveteam@straive.com to have a walkthrough of the benefits of deploying SDP.